

@Roy-Mustang Да ты прав спасибо, нужно 1|2|3
Как спарсить все абзацы в текстовом блоке (скриншот прикрепляю)?
-
Здравствуйте!
Вчера весь вечер просидел в попытках решить эту проблему... но все безрезультатно, уже если честно вообще немного расстроился даже... Не знаю, может у кого-то есть идеи, как это решить...
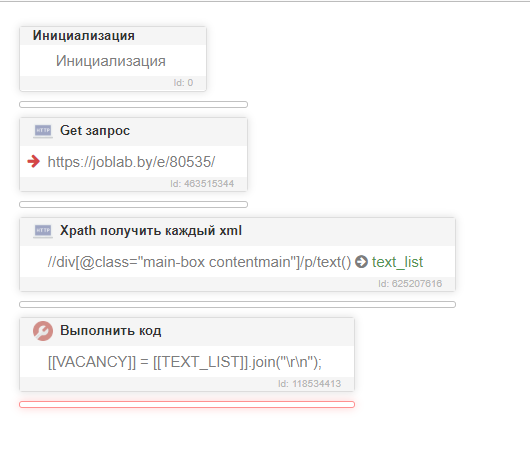
Хотел спарсить текст на сайте с описанием компаний. Но там проблема - у каждой компании большой текст, где-то 5 абзацев, где-то 10, а то и больше...
Но BAS не видит весь этот блок описание... можно выбрать только какой-то один абзац...
Примеры страниц, про которые я говорю и скриншот:
https://joblab.by/e/80535/
https://joblab.by/e/31527/Т.е. я хотел извлечь вот этот текст:
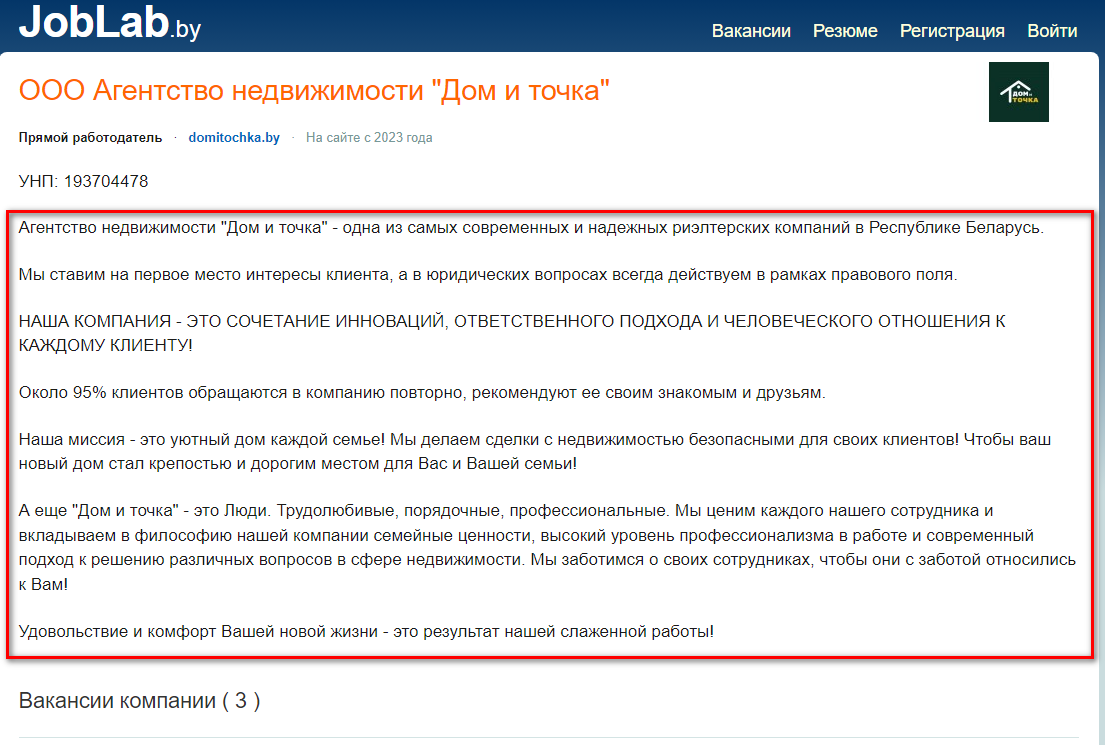
Но при попытке его извлечь в BAS у меня примерно следующее (можно выбрать только 1 абзац). Т.е. синим отметил, что я бы хотел спарсить, а красным - это то что получается выбрать в BAS:
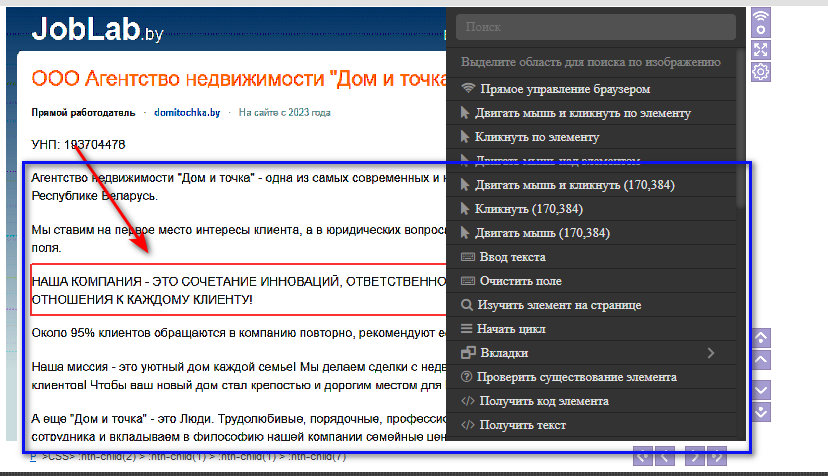
-
-
-
@sergerdn Подскажите, я неправильно делаю? Может другое действие надо выбирать?
Вот сейчас сделал так как на скриншоте...
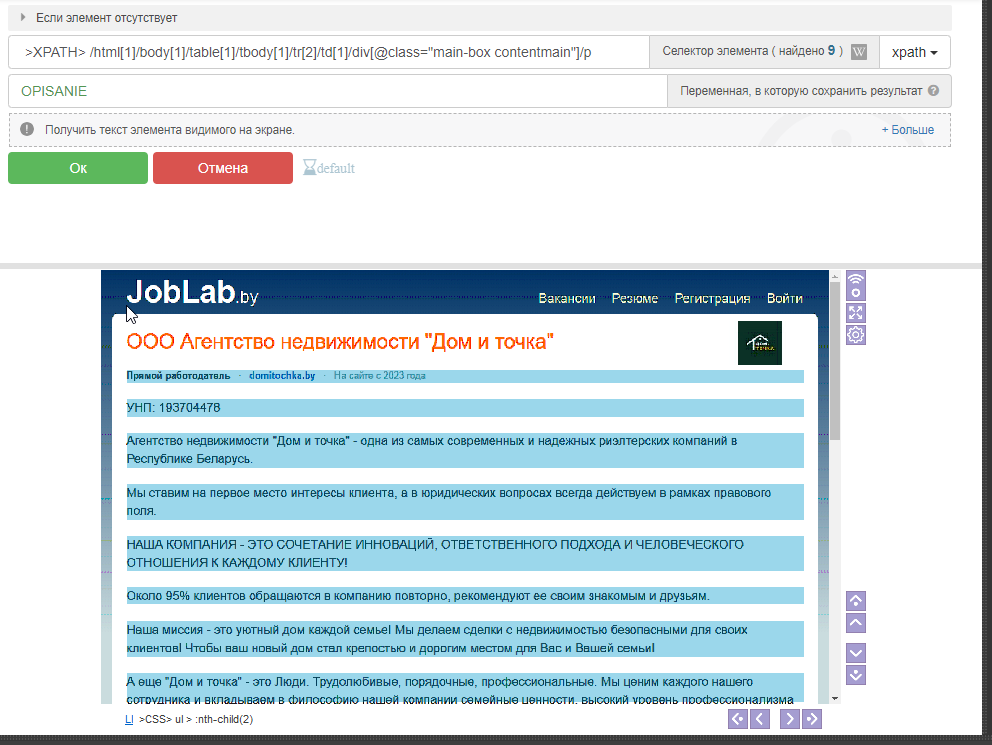
а в файл записалась все равно только 1 строчка (хотя BAS выделяет 9 элементов), может знаете как сделать чтобы сразу все 9 шт. добавлялись? похоже я что-то не так делаю(((
вот результат этого действия сейчас:
Прямой работодатель · domitochka.by · На сайте с 2023 года -
Ну у этих параграфов же есть родитель?
Почему бы не взять текст из родителя? -
Посмотрел верстку страницы: https://joblab.by/e/80535/ - сделано, конечно, через Ж немножечко )))
В родителе, присутствуют и заголовок, и тех информация...
Тогда есть другой вариант:- Считаем число подходящих P на странице, через соответствующий пункт в контекстном меню
- Через массив FOR перебираем каждый параграф, выдергивая содержание, обращаясь к нему напрямую, через >AT>[[CYCLE_INDEX]]
- Записываем это в список, если нужен каждый отдельный параграф, либо сразу плюсуем к строковой переменной.