@Fox Спасибо большое, сработало
Как не терять данные из ресурса?
-
Всем привет. Я новичок, делаю первые шаги.
Построил из кубиков простейший парсер, пока объясню на словах. В нем в качестве ресурса подключены два текстовых файла. Из первого файла скрипт последовательно берет строки с входными данными (при этом в ресурсе выбран режим "использовать один раз"), вводит их на нужном сайте, из результатов поиска берет, что нужно, и сохраняет это во второй файл. В общем, классика.
Так вот, при работе иногда сайт не загружается, и тогда в логе появляется красная надпись: "Поток завершился с сообщением: "Не удалось дождаться полной загрузки страницы". Хоть у меня действие с загрузкой сайта обернуто в игнорирование ошибок, и после этого стоит проверка на наличие ошибки, если она была, то идет по метке возврат снова к загрузке страницы. Я рассчитывал, что при таком подходе страница в любом случае будет рано или поздно загружена, но почему-то так происходит не всегда, и поток завершается.
При этом, как я понимаю, строка из файла с входными данными удаляется, т.е. по сути остается неиспользованной.
Можно ли как-то сделать, чтобы она не пропадала, а, например, чтобы такие строки хотя бы сохранялись в отдельный файл для последующего использования? Если да, как это можно сделать?
Спасибо.
-
Ставьте сперва проверку на Заглушку, и снимайте Часики с Загрузки Браузера или ставьте больше в зависимости от Сайта, тяжести его так сказать :)))
Я всегда убираю Часики и просто Цикл проверки, того или иного, там вот если как у вас Выбивает, то вот без Часиков этих, он Заглушку Гугла скорей всего покажет :)
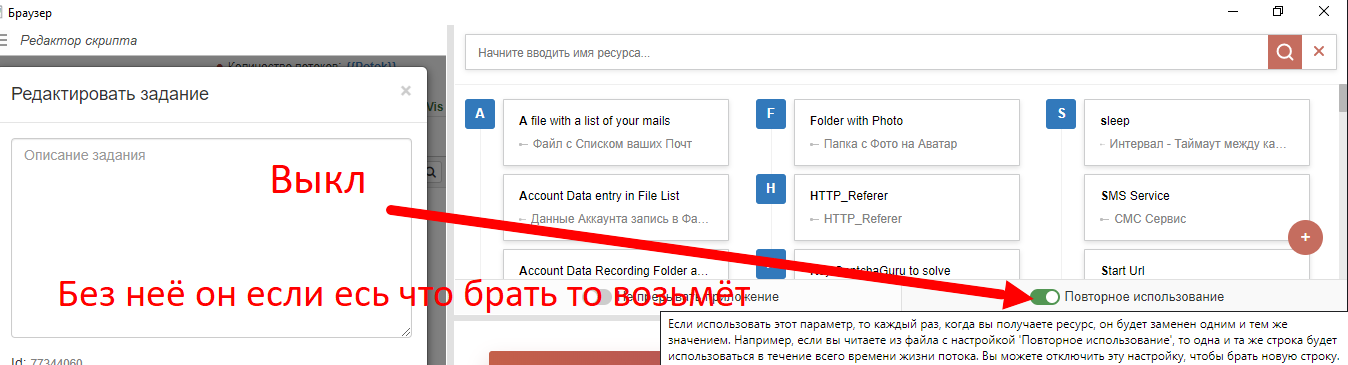
-
Спасибо за ответ. Хотя, честно говоря, не совсем понял всё, что вы сказали, особенно второй абзац. Например, про заглушку гугла - это что?
Насчет повторного использования, то мне нужно, чтобы каждая строка использовалась только один раз. Ведь если она будет использоваться несколько раз, то и результаты парсинга в конечном файле будут дублироваться, да и многократное использование - это лишнее время и ресурсы машины.