Пойми как тебе можно помочь если не данных для проверки, скинь код для проверки.
Проблема с разгадкой картинки через API ocr.space
-
Пытаюсь отправить png картинку заранее прочитанную в base64 в пер [[FILE_CONTENT]] на сервис разгадывания https://ocr.space/OCRAPI , но они отвечают что якобы это не base64
{"OCRExitCode":3,"IsErroredOnProcessing":true,"ErrorMessage":["Not a valid base64 image. The accepted base64 image format is 'data:<content_type>;base64,<base64_image_content>'. Where 'content_type' like 'image/png' or 'image/jpg' or 'application/pdf' or any other supported type."],"ErrorDetails":"Not a valid base64 image. The accepted base64 image format is 'data:<content_type>;base64,<base64_image_content>'. Where 'content_type' like 'image/png' or 'image/jpg' or 'application/pdf' or any other supported type.","ProcessingTimeInMilliseconds":"0"}Подскажите, кто юзал\юзает этот сервис через api какая правильная структура в postData для отправки картинки?
Вот что я прописываю, и он ругается что это не base64:
-
@Nikolas said in Проблема с разгадкой картинки через API ocr.space:
data:<content_type>;base64,<base64_image_content>'. Where 'content_type' like 'image/png'
smeni content-type
-
@clarabellerising
так у меня же уже стоит верный контент тайп:base64Image=data:image/png;base64,[[FILE_CONTENT]]т к картинка изначально является png картинкой
-
проблема решена! Вот готовое решение, может кому-то будет полезно:
открываем конструктор запросов и заполняем поля.
Вот содержание всех полей:
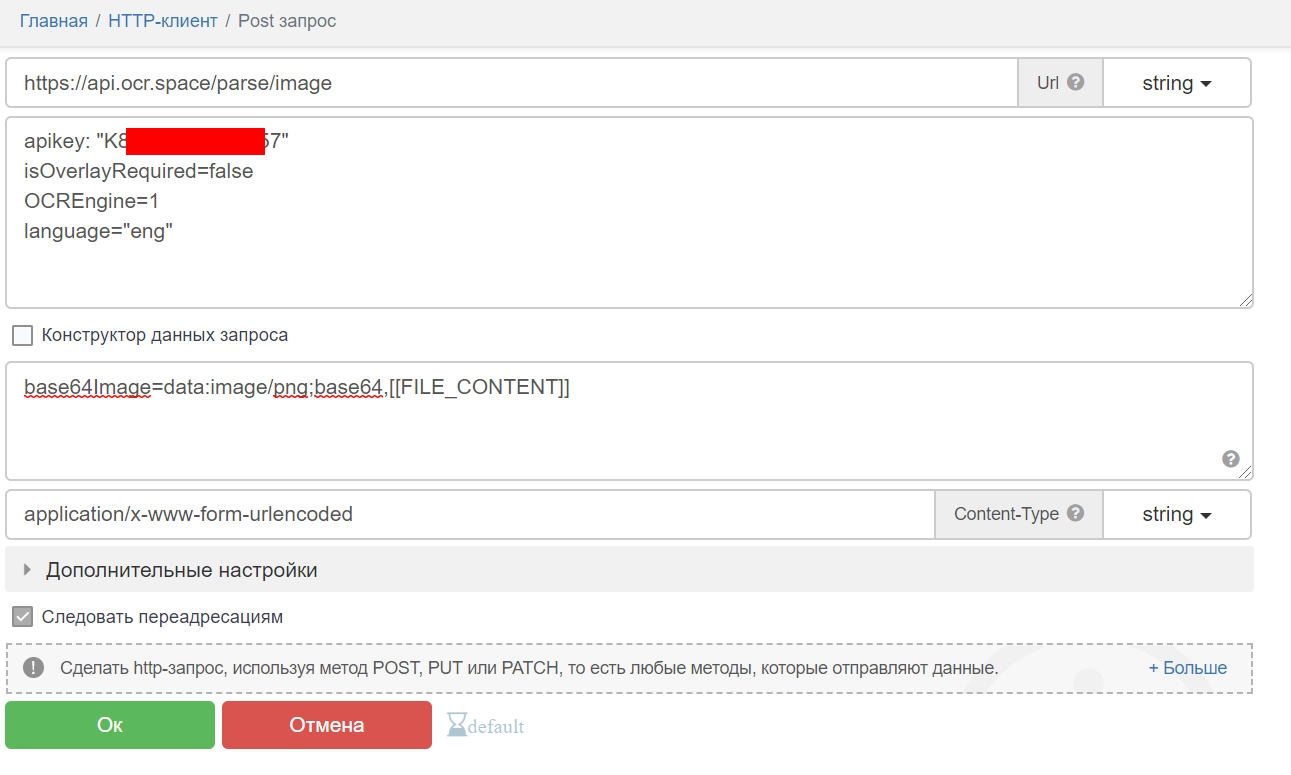
url:https://api.ocr.space/parse/imageТакой заголовок , где в переменой [[API_KEY]] текст апи ключа :
apikey: [[API_KEY]]текст Post Data:
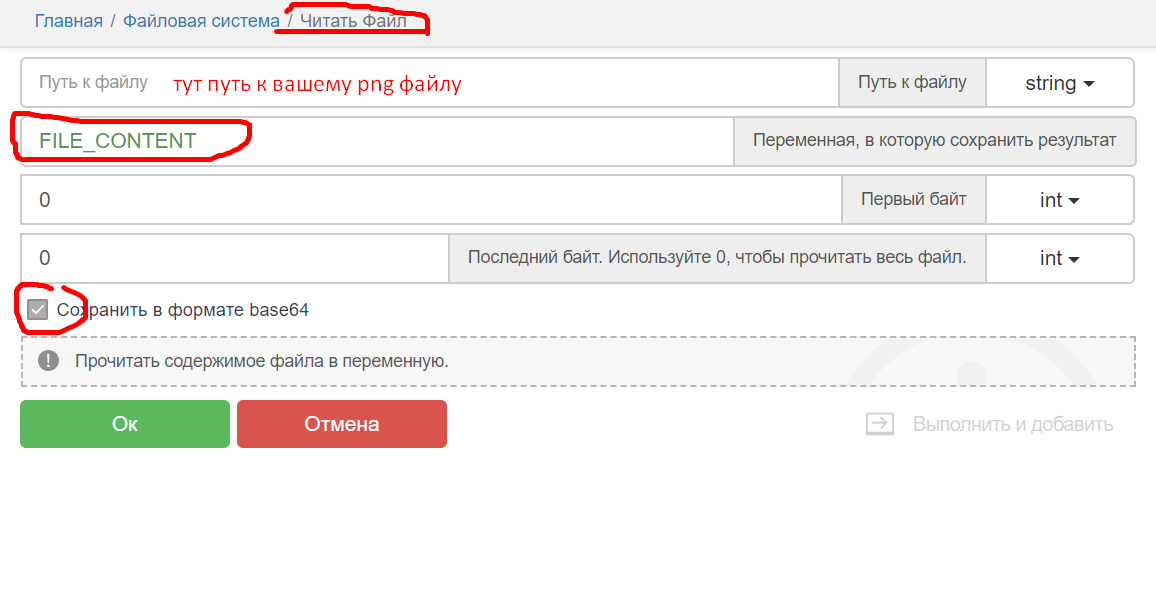
"base64Image","data:image/png;base64," + [[FILE_CONTENT]]где в [[FILE_CONTENT]] стоит base64 строка заранее прочитанной png картинки вот так:
Тип содержимого:
urlencodeСкриншот заполнения этими данными полей кубика Post запрос:
-
-
-
Вобщем, после долгих тестов я понял что параметры для лучшего распознавания нужно немного изменить, иначе если текст не четкий, то только 20% картинок ему удается разгадать, да и на тех половина текста это "кракозябры"
Вот новые параметры для распознования png картинок которые намного лучше распознают даже корявый или размытый текст в 10\10 случаях:
Url:
https://api.ocr.space/parse/imageЗаголовки:
apikey: [[API_KEY]]Жмем галку Конструктор данных запроса и заполняем:
Post Data:"language","eng","isOverlayRequired","false","base64Image","data:image/png;base64," + [[FILE_CONTENT]],"iscreatesearchablepdf","false","issearchablepdfhidetextlayer","false","filetype","png","OCREngine","2"Тип содержимого
urlencodeне забываем предварительно указать в переменной [[API_KEY]] ваш апи ключ, вот таким текстом:
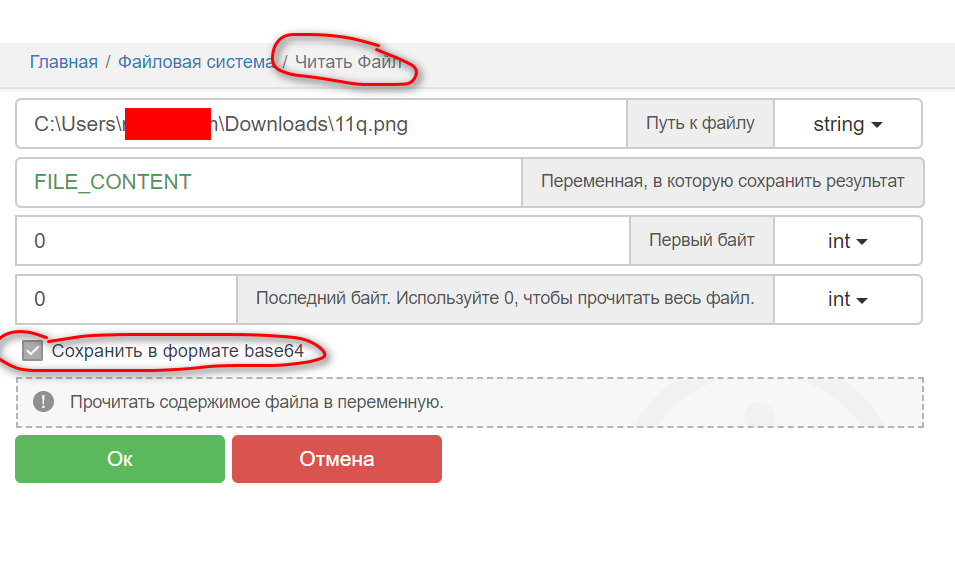
K8501**тутскрылчасть***57а в переменой [[FILE_CONTENT]] заранее прочитать картинку юзая кубик Читать файл с включенной галкой Cохранить в формате base64