
 видимо что-то делаю не так.
видимо что-то делаю не так.

Делаешь проверку, что номер потока равен 1,
В if делаешь действие спать в 300 секунд, потом действие "Прервать скрипт"
Пока писал, понял что вам тогда придется каждый раз запускать скрипт...
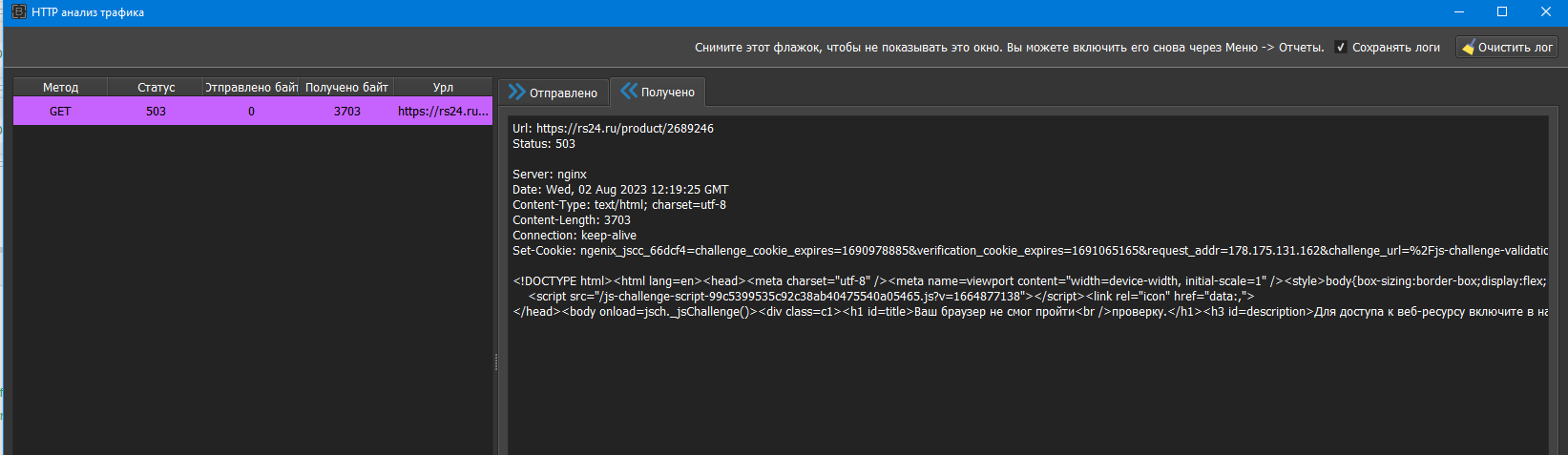
Доброго времени суток. При обработке сайтов с проверкой браузера (обязательно должен быть включен js) эта самая проверка проходит при каждом обращении к новому урл. Возможно ли как-то пройти ее например 1 раз, тем самым ускорить получение информации? link text
Сам проект просто перебирает урлы и сохраняет html
@Kreol2013 вангую что опять ja3. Юзай кастом курл с форума. Подробнее ищи на форуме по "ja3" инфы достаточно
@Q_Q said in Как обойти проверку браузера при каждом открытии нового урл:
@Kreol2013 вангую что опять ja3. Юзай кастом курл с форума. Подробнее ищи на форуме по "ja3" инфы достаточно
это первое что я проверил, но нет, там какой то хитрый трик с nginx - Вроде все заголовки такие же как и в браузере, но футболит - 400 - bad request ...
Сильно не ковырял, но, что-то там интересное ...
Скорее всего кука на каждый запрос меняется ...
Тут возможно @UserTrue опытным взглядом глянув, сможет сказать, что к чему.
@Kreol2013 said in Как обойти проверку браузера при каждом открытии нового урл:
эта самая проверка проходит при каждом обращении к новому урл.
Не смог повторить. Проверка была только при первом посещении страницы, далее покликал по ссылкам - проверки не увидел. Может быть проверка повторяется спустя некоторое время.
Update:
спустя длительное время(больше полутора часов) рефрешнул страницу, повторной проверки не увидел.
Если надо собирать данные с сайта, то можно:
// открыта в браузере другая страница - https://rs24.ru/product/3154253, но запрос проходит
// кукисы браузер отправляет автоматически
// в примере есть и headers, вероятно, это не обязательно отправлять такую портянку их
const response = await fetch("https://rs24.ru/search.htm?m=1&N=20000061", {
"headers": {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "en-US,en;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua": "\"Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"115\", \"Chromium\";v=\"115\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1"
},
"referrer": "https://rs24.ru/product/3154253",
"referrerPolicy": "strict-origin-when-cross-origin",
"body": null,
"method": "GET",
"mode": "cors",
"credentials": "include"
});
if (response.ok) {
const body = await response.text();
console.log(body);
} else {
console.error('Failed to fetch data:', response.status, response.statusText);
}
@DuckDuck said in Как обойти проверку браузера при каждом открытии нового урл:
Сильно не ковырял, но, что-то там интересное ...
Не обязательно, например:
Именно поэтому и не работает копирование всех данных(включая кукисы), что отправляет браузер. Так как новое соединение, а значит локальный порт тоже будет новый, так как так работает TCP/IP.
P.S.
выше всего лишь гипотеза, знать не знаю, что там за проверки у сайта.
P.P.S(added):
https://www.ngenix.net/
Судя по сайту поставщика решения для защиты, вероятно, он смотрит TCP/IP стэк. Все подобные сервисы это делают, кто фильтрует трафик для защиты от DDOS.
@sergerdn said in Как обойти проверку браузера при каждом открытии нового урл:
в контексте браузера запрашивать страницы и сохранять данные(в той же вкладке):
ткните, пожалуйста, где почитать как это делать. Не совсем я понял как это реализовывать.
@Kreol2013 Кубик - Браузер - Яваскрипт. Чтоб передать в него свои переменные и обратно просто пишете вместо js переменных [[моя переменная]]
const response = await fetch("[[my_target_url]]", {
"headers": {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "en-US,en;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-ch-ua": "\"Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"115\", \"Chromium\";v=\"115\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1"
},
"referrer": "https://rs24.ru/product/3154253",
"referrerPolicy": "strict-origin-when-cross-origin",
"body": null,
"method": "GET",
"mode": "cors",
"credentials": "include"
});
if (response.ok) {
const body = await response.text();
console.log(body);
[[body]] = body;
} else {
console.error('Failed to fetch data:', response.status, response.statusText);
[[get_err]] = "true"
}
@DuckDuck said in Как обойти проверку браузера при каждом открытии нового урл:
Так можно тот же клауд фактически на запросах проходить ...
С добрым утром :-))))
У меня половина скриптов состоит из микса с кодом в браузере. Но это возможно отследить самим сайтом, поэтому надо тут подходить с умом, понимая, что ты делаешь и чем это может грозить.
@DuckDuck said in Как обойти проверку браузера при каждом открытии нового урл:
Из этого прям отдельный модуль можно запелить типо http в контексте браузера.
Идея не новая. К примеру, https://www.cypress.io/, работает целиком в браузере(код для тестов бандлится в один файлик и загружается в браузер во время выполнения теста).
С добрым утром :-))))
оно мне без надобности, но часто видел сообщения на форуме что на запросах проблемы с ja3, а модуль альтернативный который, хоть и проходит, но в многопотоке жалуются что не работает.
А ты предложил решение, которое по сути закрывает эту проблему, без использования доп модулей.
Так что респект.
P.S: Ссори, за то что негативно о тебе отзывался. Но в том контексте откровенно все подбешивать стали, не уловив сути потребностей разработчика.
Если оформишь это решение в виде модуля - то репу себе хорошо поднимешь.
@DuckDuck said in Как обойти проверку браузера при каждом открытии нового урл:
А ты предложил решение, которое по сути закрывает эту проблему, без использования доп модулей.
Это ни разу не решение, браузер будет использоваться в каждом потоке. Когда нужно большое число потоков, либо частая смена прокси это решение не подойдет. К тому же нужно загрузить какую-нибудь страницу сайта, чтобы не было проблем с CORS
Это ни разу не решение, браузер будет использоваться в каждом потоке. Когда нужно большое число потоков, либо частая смена прокси это решение не подойдет. К тому же нужно загрузить какую-нибудь страницу сайта, чтобы не было проблем с CORS
Ну нагрузка то будет только на первой загрузке странице, а дальше норм. Я так полагаю можно уменьшить количество qt - и половинчатое решение как бы есть.
Согласен, что лучше обновить либу curl.
Но вот в данном случае вроде не от ja3 зависит, не смотрел этот сайт ?
@DuckDuck said in Как обойти проверку браузера при каждом открытии нового урл:
Но вот данном случае вроде не от ja3 зависит, не смотрел этот сайт ?
Не смотрел, своих сайтов хватает )