alt text
По такому же принципу можно сделать перебор массива из переменной, используя foreach
Прежде всего, большой привет всем здесь присутствующим.
Вы - замечательное сообщество!
BAS - влажная мечта каждого ботаника :-)
К сожалению, мне нужна помощь.
Я создал автоматизацию для Google, цель которой - генерировать трафик Google для определенных ключевых слов.
Я могу сделать это с помощью метода click, но, к сожалению, он не всегда работает, потому что положение результата всегда меняется.
Поэтому мне нужно иметь возможность сканировать каждую страницу результатов поиска в поисках определенных ссылок и нажимать на них, как только появляется ссылка из моего списка.
Как лучше всего решить эту проблему?
До сих пор мне, к сожалению, удавалось только искать ключевые слова, а затем нажимать на результат X на странице X, но когда порядок результатов меняется или целевой URL внезапно оказывается на другой странице результатов, это больше не работает.
Извините за плохое написание, я использую DeepL для перевода.
Большое спасибо за вашу помощь!
https://www.educba.com/xpath-contains/
https://www.google.com/search?q=xpath+contains&oq=xpath++contains
вместо text() используйте .
Разбиваете блоки выдачи на элементы и проходите по ним циклом проверяя код элемента. Если в нем нашли нужный сайт то переходим, нет идем дальше.
Начинайте цикл по тегам выдачи, в цикле получайте код каждого эллемента. В этом эллементе. Регулярным выражением или обрезкой строки находим адрес сайта или заголовок страницы и с помощью if сравниваем с искомым. Соглашаюсь с предыдущим оратором. Подумал, что стоит немного подробнее написать из за языковой разницы.
@Xuiplop тебе нужно использовать xpath/match и циклы.
0) цикл for по всем страницам, начинаем с первой и до последней.
Товарищи циклисты - вы бы хоть xpath научились бы пользоваться, жизнь проще бы показалась.
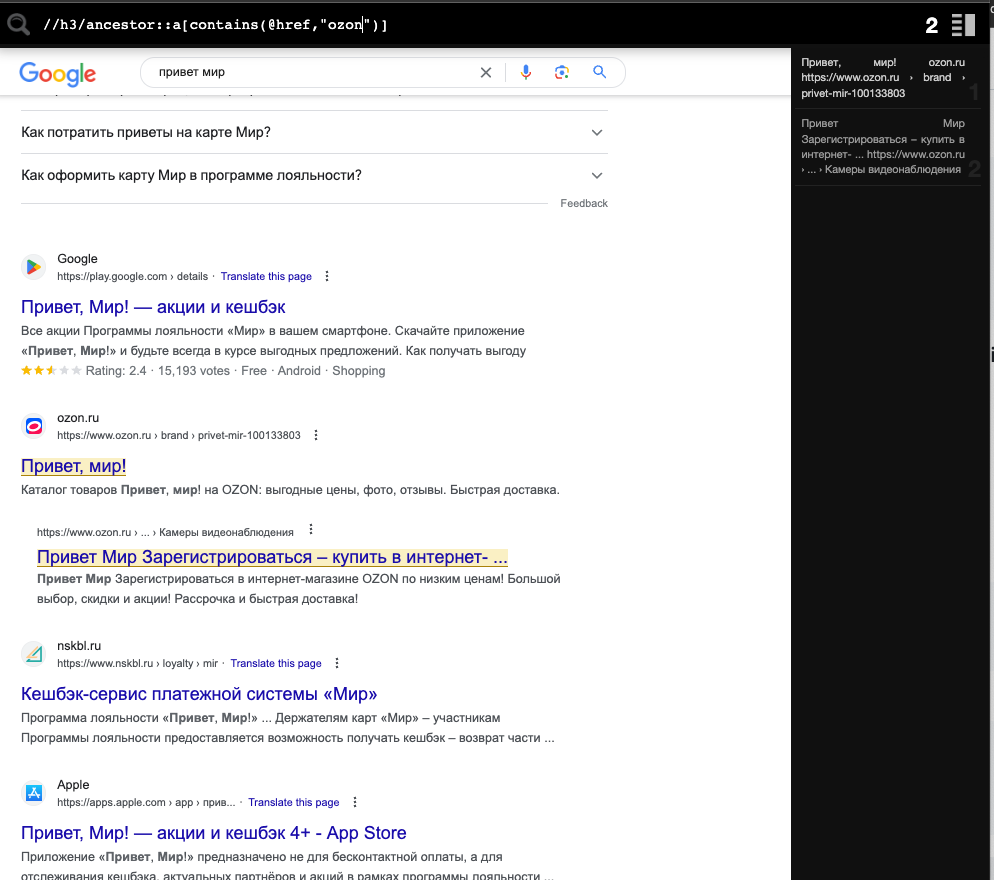
https://www.google.com/search?q=привет+мир
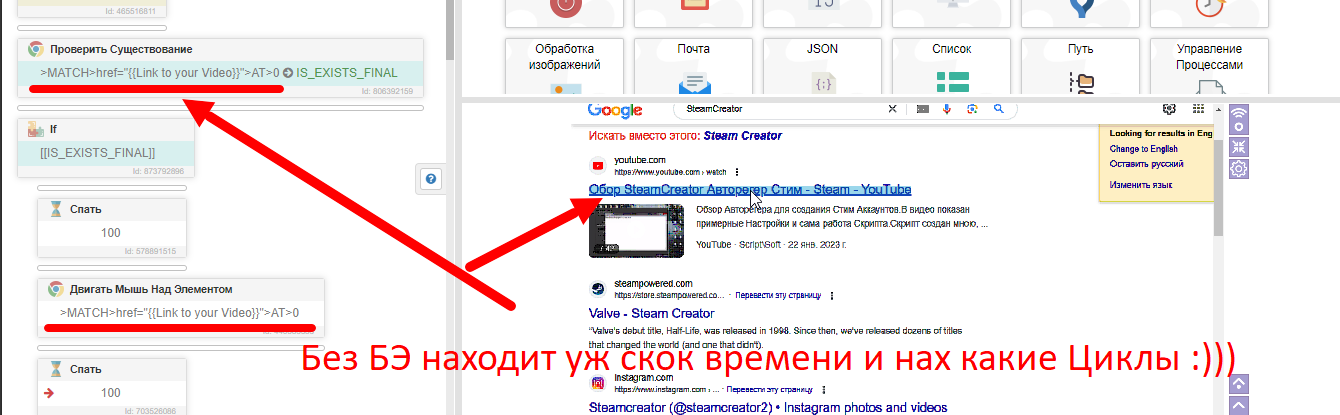
делаем проверку существования
//h3/ancestor::a[contains(@href,"ozon.ru")]
если нету идем дальше
@DuckDuck Циклом и частичным движением мышки (наведение, пропуски и так далее) вы хоть как то с имитируете жизнь, а таким способом будет явно не комильфо. Особенно в тот момент когда сайт в конце страницы выдачи.
До кучи еще эмуляцию мыши рубаните. Будет вообще быстро.
@DuckDuck said in Найти ссылку в Google:
Товарищи циклисты - вы бы хоть xpath научились бы пользоваться, жизнь проще бы показалась.
https://www.google.com/search?q=привет+мир
делаем проверку существования//h3/ancestor::a[contains(@href,"ozon")]если нету идем дальше
Это только поверхостный случай, там потом будет ещё 100500 случаев когда такая ссылка не нужна, например в вопросах и ответах
@FastSpace Во первых, скорее всего ссылка на вопросы и ответы будет содержать домен гугла, а не домен поциента. Во вторых, легким движением руки добавляем and not contains и дописываем что угодно по логике.
Но зачем предлагать ерись с циклами, регулярками и списками - не понятно, если все можно сделать средствами xpath.
@DuckDuck Главное что бы работало, ну и по Ссылке лучше ведь, а не по названию, так как реал Fast же однако выше сказал, что может быть похожих Элементов Имен больше.
Вот так как у меня он долгое время живёт и он и указывает на Заголовок, а поставь 1 и однако под строку и тп пойдёт :)
Ништяк Тема с многими примерами Ответов, в Поиске мож кому легче будет искать, кто им Пользоваться умеет правда :)))
@Alex84 У меня по части ссылки ищет - в выдаче может быть несколько страниц встречающихся по разным запросам - можно искать просто по вхождению домена.
Скажем есть сайт X.
куча запросов - типо кровля - ссылка одна,
кирпич - ссылка другая. Но в каждой ссылке будет домен пациента. Мой пример будет работать во всех этих запросах.
Отсеять лишние случайности можно с помощью добавления and not contains - и указать например домены гугла, домены рекламы гугла, вопросов и ответов и так далее.